How to keep duplicate WordPress content out of search engines
Last year I discovered that some of my content had been deleted from Google’s index. After confirming that Googlebot could still access the post in question and excluding every possibility of accidentally blocking Googlebot (robots.txt, firewall rules etc.), I opted to resubmit the post for indexing using Google search console.
The re-indexing worked as expected and I wrote it off as a glitch. However, 48 hours later the post got wiped from the index again. The deleted post was still available from Google’s index in the form of archived entries, but the canonical (preferred) URL was no longer available.
Out of ideas, I decided to make an effort to keep duplicate content away from search engines. WordPress in its infinitive wisdom will duplicate your content in almost infinite ways.
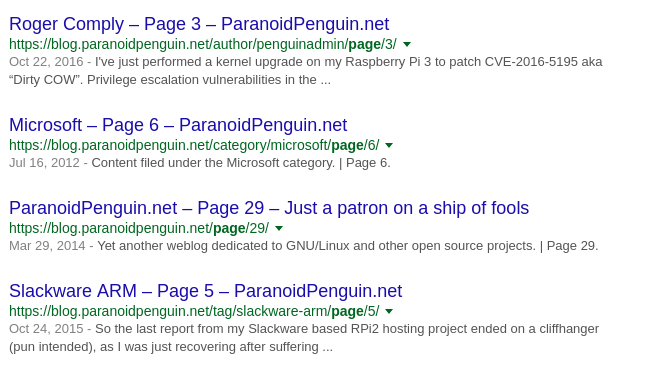
Ermm.. was anybody looking for page 29 of this thing?
Let’s look at the following post: blog.paranoidpenguin.net/2015/11/slackware-linux-is-moving-to-eudev/ that was posted in “GNU/Linux, Slackware Linux” and tagged with “eudev, Slackware, systemd, udev“. The following resources are available:
Author: /author/penguinadmin/page/13/ Category: /category/gnu-linux/page/10/ /category/gnu-linux/slackware-linux/page/6/ Paged navigation: /page/13/ Search: /?s=eudev Tags: /tag/eudev/ /tag/systemd/ /tag/udev/ /tag/slackware/page/4/ Year: /2015/page/2/ Month: /2015/11/
Awesome, eleven additional links available for indexing. I’ll be a good netizen and stop cluttering the search engines with all this junk and keep paged entries, archives and search results out of the equation.
I do believe the recommended approach is to use the robots meta tag, so I’ll be using content=”noindex,follow” to exclude content and content=”index,follow” to request indexing.
I’ll add a few lines of code to my theme’s header.php to add the robots meta tag inside the <head/> section. I’m only requesting indexing of posts and pages, in addition to the first category page (of each category).
<?php
// Don't index any paged content
if (is_paged()) {
echo '<meta name="robots" content="noindex,follow"/>';
// Archive pages, attachments and search results
} elseif (is_archive() || is_attachment() || is_search()) {
// Allow indexing of the first category page only
if (!empty(get_query_var('category_name'))) {
echo '<meta name="robots" content="index,follow"/>';
} else {
echo '<meta name="robots" content="noindex,follow"/>';
}
// Regular content
} else {
echo '<meta name="robots" content="index,follow"/>';
}
?>My issue with pages being deleted from Google’s index sorted itself out before I could implement any of my planned enhancements. Maybe it was a glitch after all. From what I’ve read, Google will not penalize your site for having duplicate content. It’s all a myth they say.